
Finding a Needle in the Haystack: Querying Physical AI Data with Daft
Pose + semantic search over Apple's EgoDex hand-manipulation dataset with Daft: SigLIP embeddings meet hand-pose geometry. Ctrl+F for physical AI data.
by Shreyas GarimellaTL;DR
We ran Daft on Apple's EgoDex and showed what Daft makes possible: searching on video using natural language queries combining frame-level semantic embeddings and geometric features, i.e., “find every clip in my dataset where a writing-gripped hand lifts chopsticks.” Using Daft, you can now CTRL+F over your robotics dataset.
The Menu Problem
Historically, robots have performed tasks listed on a pre-defined menu. An Amazon Kiva used to only need to know how to move shelving pods from storage to picker stations. Your Roomba only needs to know how to clean your floor. This made dataset curation somewhat hand-curatable. Using carefully set up experiments, a researcher or engineer could easily generate data for a specific task. Contents of the dataset were easily known by construction.
| Amazon Kiva | Roomba |
|---|---|
 |  |
In uncontrolled environments, that assumption falls apart. When training a clothes-folding robot, you can’t enumerate every garment configuration in advance. So instead of designing experiments, you outfit humans with head-mounted cameras and let them fold, reach, and grasp, hoping that the world provides the variation needed to capture the full distribution of data. That data doesn’t come labeled. When you need to later audit your training mix or retrain on failure cases (like a tangled sleeve, silk blouse, inside-out sock), you have no idea where those moments are.
Scale that up even further: A fleet of 500 autonomous vehicles uploads petabytes of video and sensor data to the cloud every day. How do you, as a researcher, identify your near crashes and traffic violations amongst hundreds of 100k+ hours of video for re-training?
Your data is no longer served off a menu. The data just arrives, continuously growing faster than anyone could understand it, and what’s in it isn’t well-known: it needs to be discovered. How do you retrieve a specific subset of data based on unlabeled multimodal features for downstream task fine-tuning? How can you find difficult edge cases and failures within your data?
This is the data understanding problem most frontier robotics labs are facing.
Finding a Needle in the Haystack: EgoDex
EgoDex is Apple’s egocentric dataset consisting of paired hand pose annotations and head-view video across varying tabletop tasks. It’s full of unique scenarios and rich sensor and video data, making it a perfect candidate for multimodal understanding.
But it runs into the menu problem. For example, the task description “fold a small t-shirt on a wooden table while sitting” obscures some important geometric and visual primitives.
How can I tell if my training mix is short on twisting actions?
How can I select a subset of episodes where the person holds something with a tight hammer grip?
Let's see how Daft can provide the solution.
Ingesting the EgoDex Dataset
In the HDF5 file format, a single file holds many named n-dimensional arrays plus metadata, like a tiny filesystem per file. Since EgoDex as well as many other robotics datasets come packaged in the HDF5 format, we decided to write a new Hdf5File type with native support in Daft, alongside existing types like VideoFile, AudioFile, etc.
Download the raw EgoDex dataset from Apple here:
mkdir -p .data
curl "https://ml-site.cdn-apple.com/datasets/egodex/test.zip" -o .data/test.zip
unzip .data/test.zipEvery EgoDex episode is one {i}.hdf5 (the hand-pose transforms) sitting next to a corresponding {i}.mp4 (the head-cam video). We write a method, read_egodex turns that whole dataset into a single per-frame DataFrame in Daft:
from egodex_lib.egodex import read_egodex
# Raw EgoDex HDF5 → one row per frame, straight into Daft.
df = read_egodex(".data/**/*.hdf5", with_video=True)HDF5 to Daft Implementation Details
daft.from_files yields one row per HDF5 file. A single @daft.func UDF opens each file through the native Hdf5File API, batch-reads every transform it needs in one call, runs NumPy feature math (build_state, build_skeleton, build_extrinsics), and returns the episode as a list of per-frame structs. We then run an explode then fans that list into one row per frame with the task broadcasted.
@daft.func(return_dtype=EPISODE_DTYPE)
def process_egodex_episode(file_: daft.File) -> dict:
h = file_.as_hdf5()
transforms = h.read(list(dict.fromkeys(STATE_TRANSFORMS + SKELETON_TRANSFORMS + [CAMERA])))
state = build_state(transforms)
skeleton = build_skeleton(transforms)
extrinsics = build_extrinsics(transforms)
action = next_frame_action(state)
task = resolve_task(h.attrs()) # native attrs() returns a dict
frames = [
{
"frame_index": i,
"observation.state": state[i],
"observation.skeleton": skeleton[i],
"observation.extrinsics": extrinsics[i],
"action": action[i],
}
for i in range(len(state))
]
return {"task": task, "frames": frames}def read_egodex(hdf5_glob, with_video: bool = False):
per_file = Window().order_by(col("file").file_path())
episodes = (
daft.from_files(hdf5_glob)
.sort(col("file").file_path())
.with_column("episode_index", row_number().over(per_file) - 1)
# carry the HDF5 path so the video decoder can find each episode's sibling .mp4
.with_column("_src", col("file").file_path())
.into_batches(8)
.with_column("_ep", process_egodex_episode(col("file")))
.with_column("task", col("_ep")["task"])
.with_column("frames", col("_ep")["frames"])
)
frames = (
episodes.explode("frames")
.select("episode_index", "task", "_src", col("frames").unnest())
.with_column("timestamp", (col("frame_index") / FPS).cast(DataType.float32()))
)
if with_video:
frames = frames.with_column("observation.image", _decode_sibling_mp4(col("_src"), col("timestamp")))
return frames.exclude("_src")Here's what your dataframe output should look like after reading the first 3 rows:

Here are some example videos (abridged schemas):
| episode_index | frame_index | task | observation.state | observation.skeleton |
|---|---|---|---|---|
<ep> |
<f> |
varies per clip below | [48 floats] | [204 floats] |
| Fold a small tshirt on a wooden table while sitting. | ||||
| Pick up food with chopsticks. | ||||
| Assemble a chair while sitting at a table. | ||||
| Sweep the marbles into a pile. | ||||
| Remove lids from three cups on a wooden table. | ||||
| Unstack four cups. | ||||
What's in Each Frame: SigLIP Embeddings
Now, using Daft, we'll run Google’s SigLIP-2 image encoder over a subsampled set of frames (1 fps), across episodes, and store the result as a vector_column in the Daft DataFrame.
from daft import DataType, Series
from transformers import AutoModel, AutoProcessor
import torch
def _auto_device() -> str:
if _HAS_CUDA:
return "cuda"
if torch.backends.mps.is_available():
return "mps"
return "cpu"
_HAS_CUDA = torch.cuda.is_available()
GPUS = 1 if _HAS_CUDA else 0
DEVICE = os.environ.get("CLIP_DEVICE", _auto_device())
DTYPE = torch.float16 if DEVICE == "cuda" else torch.float32
SUBSAMPLE = 30 # keep 1 of every 30 frames (~1 fps); semantic content barely changes between adjacent frames
MODEL_ID = "google/siglip2-base-patch16-224"
EMB_DIM = 768 # SigLIP2-base shared image/text embedding dim (must match the model)The encoder is wrapped in a @daft.cls, which is a stateful UDF. Unlike plan UDFs, a class UDF instantiates once per worker and stays in GPU memory to be reused across all batches:
def _normalized_embedding(model_output) -> torch.Tensor:
"""Pull the embedding tensor out of a transformers output and L2-normalize it.
transformers 5.x returns a model-output object from get_image_features /
get_text_features; older versions returned a bare tensor. Handle both.
"""
if torch.is_tensor(model_output):
feats = model_output
else:
feats = model_output.pooler_output
feats = feats.float()
return feats / feats.norm(dim=-1, keepdim=True) # unit-norm so cosine == dot product
@daft.cls(gpus=GPUS, max_concurrency=1, use_process=False)
class SiglipEmbedder:
def __init__(self) -> None:
self.model = AutoModel.from_pretrained(MODEL_ID, torch_dtype=DTYPE).to(DEVICE).eval()
self.processor = AutoProcessor.from_pretrained(MODEL_ID)
@daft.method.batch(return_dtype=DataType.embedding(DataType.float32(), EMB_DIM), batch_size=16)
def embed_image(self, images: Series):
# images.to_pylist() yields uint8 H×W×C numpy arrays; the SigLIP processor takes them
# directly (verified identical to the PIL path), so no per-frame Image.fromarray needed.
inputs = self.processor(images=images.to_pylist(), return_tensors="pt").to(DEVICE)
with torch.no_grad():
model_output = self.model.get_image_features(**inputs)
embeddings = _normalized_embedding(model_output)
return list(embeddings.cpu().numpy())from egodex_lib import egodex
from daft import col
emb = (
egodex.embed_frames(
df.where(col("episode_index").is_in(EPISODES))
)
.select("episode_index", "frame_index", "clip_emb")
.collect()
)
emb.show(3)Then, Daft streams the frames through the encoder in batches and writes each 768D vector back as a column in the DataFrame.
We embed once and reuse at query time. Later on query, a text query (”chopsticks”, “folded shirt”) will be encoded by the same SigLip model, and cosine similarity against clip_emb becomes a similarity column in the DataFrame.
What the Hands Are Doing: Geometric Features
SigLIP can tell you a frame contains chopsticks. It can’t tell you the hand holding them is in a writing grip. That’s a geometric fact that can be computed directly from the 48D wrist pose and the 204D joint skeleton in the sensor data.
We propose an abstraction for geometric scenarios in EgoDex as "states and actions".
States = a property of the hands/wrist/arms that can be computed over just one frame.
We researched hand poses using hand-surgery research, and what we discovered is that the field splits into two families: precision grips, where the fingertips and thumb delicately pinch an object, and power grips, where the whole hand wraps around it. We also classify hand openness as a state using the hand flexion model.
Actions = a property of the hands/wrist/arms that must be computed over several frames.
Lifting, for example, is characterized by the Y-position of the wrist increasing quicker than usual over time. This generalizes to most actions, where we compute some kind of metric like a rate of change to detect when an action occurs, as well as when it starts and stops.
This is a summary of which poses we detect and how we do it:
| Scenario | Type | What we compute | Image |
|---|---|---|---|
| Hand openness | State | Mean finger flexion (MCP+PIP+DIP joint angles) |  |
| Writing grip (tripod) | State | Thumb meets index/middle fingertips; ring & little more curled |  |
| Hammer grip (power) | State | All four fingers wrapped; thumb folded over the knuckles |  |
| Twisting | Action | Wrist rotation about the forearm axis (pronation/supination) |  |
| Reaching | Action | Arm extension (hand-to-shoulder distance) increasing |  |
| Lifting | Action | Wrist vertical velocity |  |
| Grasping | Action | Fingers closing (curl decreasing over time) |  |
| In-hand manipulation | Action | Wrist still while fingers actively move |  |
Each frame's sensor data encodes geometric quantities the video alone doesn't: observation.state (48 numbers, wrist + 5 fingertips per hand) and observation.skeleton (204 numbers, 68 joints).
To support detecting static poses as well as in-progress actions, we use these geometric quantities to compute states per frame as well as action rates over time and write them as columns alongside the SigLIP embeddings.
Look at how we do math to preprocess geometric quantities using Numpy & Daft!
Computing forearm roll - daft udf
@daft.func(return_dtype=DataType.float64())
def forearm_roll(rot6d, rot6d_next, forearm_axis):
"""Wrist roll (rad) about the forearm axis from one frame to the next (0 at an episode's last frame)."""
if rot6d is None or rot6d_next is None:
return 0.0
delta = _rotation_matrix(rot6d_next) @ _rotation_matrix(rot6d).T
angle = np.arccos(np.clip((np.trace(delta) - 1) / 2, -1, 1))
axis = np.array([delta[2, 1] - delta[1, 2], delta[0, 2] - delta[2, 0], delta[1, 0] - delta[0, 1]])
magnitude = np.linalg.norm(axis)
if magnitude < 1e-9:
return 0.0
return float(abs(angle * np.dot(axis / magnitude, np.asarray(forearm_axis))))Orientation from the 6-number rotation — rebuild a hand's full orientation (and the palm-facing direction) from rot6d via Gram–Schmidt:
def rotation_from_rot6d(rot6d):
"""rot6d (N, 6) -> (N, 3, 3) rotation matrices (columns = hand x, y axes + palm normal)."""
first_column = rot6d[:, 0:3]
first_column = first_column / (np.linalg.norm(first_column, axis=1, keepdims=True) + 1e-9)
second_column = rot6d[:, 3:6]
second_column = second_column - (first_column * second_column).sum(1, keepdims=True) * first_column
second_column = second_column / (np.linalg.norm(second_column, axis=1, keepdims=True) + 1e-9)
palm_normal = np.cross(first_column, second_column)
return np.stack([first_column, second_column, palm_normal], axis=2)The state features — fingertip distances, curl, pinch, palm orientation, aperture, all per frame for both hands:
def compute_raw_features(state: np.ndarray) -> dict:
"""Per-frame raw features for both hands, keyed by feature + hand tag ('L' / 'R')."""
features = {}
for side, tag in HAND_TAGS:
wrist, rot6d, fingertips = _split_hand(state, HAND_BASE[side])
tip_to_wrist = np.linalg.norm(fingertips - wrist[:, None, :], axis=2) # (N, 5)
features[f"fingerdist_{tag}"] = tip_to_wrist
features[f"curl_{tag}"] = tip_to_wrist.mean(1) # small = curled
palm_normal = palm_normal_from_rot6d(rot6d)
features[f"palmnormal_{tag}"] = palm_normal
features[f"palm_up_{tag}"] = palm_normal[:, 1] # +y component
features[f"pinch_{tag}"] = np.linalg.norm(fingertips[:, 0] - fingertips[:, 1], axis=1) # thumb-index
tip_pairs = fingertips[:, :, None, :] - fingertips[:, None, :, :]
features[f"aperture_{tag}"] = np.linalg.norm(tip_pairs, axis=3).max((1, 2)) # max tip-tip spread
features[f"wrist_{tag}"] = wrist
return featuresAngle between two vectors — the atan2 form stays stable when fingers are nearly straight or fully folded:
def angle_between(first_bone, second_bone):
"""Row-wise angle (rad, [0, pi]) between two vectors. atan2 form is stable at 0/pi."""
cross_magnitude = np.linalg.norm(np.cross(first_bone, second_bone), axis=-1)
dot_product = (first_bone * second_bone).sum(-1)
return np.arctan2(cross_magnitude, dot_product)Finger flexion — turn a finger's joint positions into bend angles (the core of "open palm vs. fist"):
def finger_flexion(skeleton, side, finger):
"""(N, n_joints) per-joint flexion angles along a finger chain.
Flexion = the angle between consecutive bone vectors (0 = straight, larger =
more curled). Non-thumb fingers yield MCP / PIP / DIP (3); the thumb yields 2.
"""
positions = [joint_position(skeleton, name) for name in finger_joint_names(side, finger)]
bones = [positions[i + 1] - positions[i] for i in range(len(positions) - 1)]
joint_angles = [angle_between(bones[i], bones[i + 1]) for i in range(len(bones) - 1)]
return np.stack(joint_angles, axis=1)Palm normal from the skeleton — fit a plane through the wrist + knuckles; the normal is the smallest-eigenvalue eigenvector, sign-fixed to face the palm:
def palm_normal(skeleton, side):
"""(N, 3) unit palm-plane normal via a best-fit plane through the knuckles."""
wrist = joint_position(skeleton, side + "Hand")
knuckles = [joint_position(skeleton, f"{side}{f}FingerKnuckle") for f in ("Index", "Middle", "Ring", "Little")]
points = np.stack([wrist] + knuckles, axis=1)
centered = points - points.mean(1, keepdims=True)
covariance = np.einsum("nki,nkj->nij", centered, centered)
_, eigenvectors = np.linalg.eigh(covariance) # ascending; [:, :, 0] = smallest
normal = eigenvectors[:, :, 0]
# orient deterministically by handedness, then flip to the palm-facing convention
index_knuckle = joint_position(skeleton, f"{side}IndexFingerKnuckle")
little_knuckle = joint_position(skeleton, f"{side}LittleFingerKnuckle")
reference = np.cross(index_knuckle - wrist, little_knuckle - wrist)
orientation = np.sign((normal * reference).sum(1))
orientation[orientation == 0] = 1.0
return normal * orientation[:, None] * PALM_SIGN[side]Arm extension — wrist-to-shoulder reach as a fraction of total arm length:
def arm_extension(skeleton, side):
"""(N,) wrist-to-shoulder distance / total arm length (0 = tucked, ~1 = straight)."""
shoulder = joint_position(skeleton, side + "Shoulder")
upper_arm = joint_position(skeleton, side + "Arm")
forearm = joint_position(skeleton, side + "Forearm")
wrist = joint_position(skeleton, side + "Hand")
arm_length = (
np.linalg.norm(upper_arm - shoulder, axis=1)
+ np.linalg.norm(forearm - upper_arm, axis=1)
+ np.linalg.norm(wrist - forearm, axis=1)
)
return np.linalg.norm(wrist - shoulder, axis=1) / (arm_length + 1e-9)Finger joints in the hand's own frame — build an orthonormal hand frame and change basis into it, so gross hand motion cancels and only finger movement remains (for in-hand manipulation):
def hand_local_joints(skeleton, side):
"""(N, K, 3) the side's finger joints expressed in the hand's own frame.
The frame is z = palm normal, x = across-palm, origin = wrist; expressing the
joints in it removes gross hand translation/rotation, leaving only the
fingers' own motion (used to detect in-hand manipulation).
"""
wrist = joint_position(skeleton, side + "Hand")
across_palm = joint_position(skeleton, f"{side}LittleFingerKnuckle") - joint_position(
skeleton, f"{side}IndexFingerKnuckle"
)
z_axis = _unit(palm_normal(skeleton, side))
x_axis = _unit(across_palm - (across_palm * z_axis).sum(1, keepdims=True) * z_axis)
y_axis = np.cross(z_axis, x_axis)
frame = np.stack([x_axis, y_axis, z_axis], axis=1) # (N, 3, 3), rows = axes
joint_names = [name for finger in FINGERS for name in finger_joint_names(side, finger)]
positions = np.stack([joint_position(skeleton, name) for name in joint_names], axis=1) # (N, K, 3)
return np.einsum("nij,nkj->nki", frame, positions - wrist[:, None, :])Wrist angular velocity — rotation speed from consecutive orientation matrices (relative rotation -> trace -> angle), one of the temporal features:
def add_angular_velocity(features, state, episode_index, frame_index, fps):
"""Add wrist angular speed (rad/s) from consecutive orientations, for the overlay table."""
for side, tag in HAND_TAGS:
rotations = rotation_from_rot6d(state[:, rot6d_slice(side)])
angular_speed = np.zeros(len(rotations))
for episode in np.unique(episode_index):
rows = np.where(episode_index == episode)[0]
rows = rows[np.argsort(frame_index[rows])]
if len(rows) < 2:
continue
relative = np.einsum("nij,nkj->nik", rotations[rows][1:], rotations[rows][:-1]) # R_t @ R_{t-1}^T
cosine = np.clip((np.trace(relative, axis1=1, axis2=2) - 1) / 2, -1, 1)
angular_speed[rows[1:]] = np.arccos(cosine) * fps
features[f"wrist_angvel_{tag}"] = angular_speed
return featuresFor States
We compute per-frame static features such as finger distance from tip to wrist, curl amount, palm normal vector, max finger tip-to-tip spread, and wrist position.
df = egodex.add_state_features(df)For Actions
We use Daft window functions over Window().partition_by("episode_index").order_by("frame_index"). These are time derivatives like wrist velocity and curl velocity that turn static poses into motion verbs like grasping and reaching.
df = egodex.add_skeleton_features(df)Look at how we use Daft row-wise UDFs and expressions to compute states
# daft expression
def openness(hand, thr, open_lo=0.0, open_hi=1.0):
"""Openness band on `hand` (1 = fully open palm), mapped onto the closure column via the
calibrated closure spread [closure_lo, closure_hi]: higher openness -> lower closure."""
span = (thr["closure_hi"] - thr["closure_lo"]) or 1.0
clo_lo = thr["closure_hi"] - open_hi * span
clo_hi = thr["closure_hi"] - open_lo * span
return (col(f"closure_{hand}") >= clo_lo) & (col(f"closure_{hand}") <= clo_hi)
# daft expression
def writing_grip(hand, thr):
"""Tripod/precision grip on `hand` from flexion + thumb-tip distance vs calibrated thresholds."""
return _is_writing_grip(
col(f"flex_nonthumb_{hand}"),
col(f"thumb_min_tip_{hand}"),
thr["curled_flexion"],
thr["curl_gap"],
thr["thumb_on_tip"],
)
@daft.func(return_dtype=DataType.bool())
def _is_writing_grip(flex_nonthumb, thumb_min_tip, curled_flexion, curl_gap, thumb_on_tip):
"""Tripod: thumb on the index/middle tip, those two not fisted, ring+little more curled."""
flex = np.asarray(flex_nonthumb)
return bool(
thumb_min_tip < thumb_on_tip
and flex[0] < curled_flexion
and flex[1] < curled_flexion
and flex[2] > flex[0] + curl_gap
and flex[3] > flex[1] + curl_gap
)
# daft expression
def hammer_grip(hand, thr):
"""Power grip on `hand` from flexion + thumb-knuckle distance vs calibrated thresholds."""
return _is_hammer_grip(
col(f"flex_nonthumb_{hand}"), col(f"thumb_min_knuckle_{hand}"), thr["curled_flexion"], thr["thumb_on_knuckle"]
)
# daft udf
@daft.func(return_dtype=DataType.bool())
def _is_hammer_grip(flex_nonthumb, thumb_min_knuckle, curled_flexion, thumb_on_knuckle):
"""Power: all four fingers curled and the thumb wrapped across a proximal knuckle."""
flex = np.asarray(flex_nonthumb)
return bool(bool((flex > curled_flexion).all()) and thumb_min_knuckle < thumb_on_knuckle)
Look at how we use Daft window UDFs to compute actions
Rates are time-derivatives over Window().partition_by("episode_index").order_by("frame_index"). We only drop to a custom @daft.func for the one thing that isn't a built-in — rotation about the forearm axis (twisting) — then smooth it with a rolling mean().over(...).
def add_skeleton_features(df, fps=DEFAULT_FPS):
"""Per-episode continuous action rates via Daft window functions over the per-frame geometry.
Differentiates the continuous quantities over time: curl / wrist-height / arm-extension by
scalar diffs, wrist & finger-joint motion by native euclidean_distance, wrist rotation by
forearm_roll (then smoothed). All native/in-DAG — no collect, no thresholds, no booleans.
Keeps the per-frame columns the query-time scenarios read (closure, flex_nonthumb, thumb mins).
Expects the output of add_state_features.
"""
dt = 1.0 / fps
per_episode = Window().partition_by("episode_index").order_by("frame_index")
smooth = Window().partition_by("episode_index").order_by("frame_index").rows_between(-2, 2)
for tag, _ in HANDS:
# euclidean_distance needs fixed-size-list inputs; materialize the casts once per hand
df = df.with_column(
f"_wrist_v_{tag}", col(f"wrist_{tag}").cast(DataType.fixed_size_list(DataType.float64(), WRIST_DIM))
)
df = df.with_column(
f"_joints_v_{tag}",
col(f"local_joints_{tag}").cast(DataType.fixed_size_list(DataType.float64(), LOCAL_JOINTS_DIM)),
)
df = df.with_column(
f"curl_rate_{tag}",
((col(f"curl_{tag}").lead(1).over(per_episode) - col(f"curl_{tag}")) / dt).fill_null(0.0),
)
df = df.with_column(
f"wrist_vert_vel_{tag}",
((col(f"wrist_height_{tag}").lead(1).over(per_episode) - col(f"wrist_height_{tag}")) / dt).fill_null(0.0),
)
df = df.with_column(
f"arm_ext_rate_{tag}",
((col(f"arm_extension_{tag}").lead(1).over(per_episode) - col(f"arm_extension_{tag}")) / dt).fill_null(0.0),
)
df = df.with_column(
f"wrist_speed_{tag}",
(
euclidean_distance(col(f"_wrist_v_{tag}"), col(f"_wrist_v_{tag}").lead(1).over(per_episode)) / dt
).fill_null(0.0),
)
df = df.with_column(
f"articulation_{tag}",
(
euclidean_distance(col(f"_joints_v_{tag}"), col(f"_joints_v_{tag}").lead(1).over(per_episode)) / dt
).fill_null(0.0),
)
df = df.with_column(
f"roll_raw_{tag}",
forearm_roll(
col(f"wrist_rot6d_{tag}"),
col(f"wrist_rot6d_{tag}").lead(1).over(per_episode),
col(f"forearm_axis_{tag}"),
)
/ dt,
)
df = df.with_column(f"roll_{tag}", col(f"roll_raw_{tag}").mean().over(smooth))
keep = ["episode_index", "frame_index"]
for tag, _ in HANDS:
keep += [
f"closure_{tag}",
f"flex_nonthumb_{tag}",
f"thumb_min_tip_{tag}",
f"thumb_min_knuckle_{tag}",
f"curl_rate_{tag}",
f"wrist_vert_vel_{tag}",
f"arm_ext_rate_{tag}",
f"wrist_speed_{tag}",
f"articulation_{tag}",
f"roll_{tag}",
]
return df.select(*keep)# A custom UDF, fed by a window: lead(1) pulls the *next* frame's wrist
# rotation into this row, and the UDF does the rotation-axis math. (twisting)
@daft.func(return_dtype=DataType.float64())
def forearm_roll(rot6d, rot6d_next, forearm_axis):
"""Wrist roll (rad) about the forearm axis from one frame to the next (0 at an episode's last frame)."""
if rot6d is None or rot6d_next is None:
return 0.0
delta = _rotation_matrix(rot6d_next) @ _rotation_matrix(rot6d).T
angle = np.arccos(np.clip((np.trace(delta) - 1) / 2, -1, 1))
rotation_axis = np.array([delta[2, 1] - delta[1, 2],
delta[0, 2] - delta[2, 0],
delta[1, 0] - delta[0, 1]])
magnitude = np.linalg.norm(rotation_axis)
if magnitude < 1e-9:
return 0.0
return float(abs(angle * np.dot(rotation_axis / magnitude, np.asarray(forearm_axis))))
Querying by State, Action, and Semantics
Now that the geometry and embeddings are precomputed, a query is just filter + rank — one function, egodex.query, whether you're asking for a pose, a semantic match, or both.
First, compute data-driven cut points for every geometric scenario once across all frames using Daft's percentile aggregations. How fast do you need to reach to count as "reaching"? What truly counts as "open" versus "closed"?
thresholds = egodex.calibrate(features)Then run your first purely pose-based query!
open_hits = egodex.query(features, pose="openness", open_lo=0.9, open_hi=1.0, k=5, thresholds=thresholds)top = open_hits[0]
egodex.overlay(DATASET, top["episode_index"], top["segments"][0][0])This filters to the frames whose hand sits in the most open band (0.9 to 1 on a scale of [0,1]) and returns the top 5 matching episodes.
Then run a semantic query. This will encode the string "shirts" with SigLIP and rank episodes by cosine similarity.
shirt_hits = egodex.query(emb, text="shirts", k=2)top = shirt_hits[0]
egodex.overlay(DATASET, top["episode_index"], top["segments"][0][0])To put it to the real test, let's try a combined query where we filter on pose="hammer grip and text="stapler":
egodex.query(feats, pose="hammer_grip", text="stapler", k=1, thresholds=thresholds)top = combined_hits[0]
egodex.overlay(DATASET, top["episode_index"], top["segments"][0][0])Under the hood: how the ranking core works
The pose scenario becomes a Daft boolean expression (.where(...) over existing columns — no model). The text query is one dot product against the clip_emb column, joined back per frame as a sim column. Then group by episode, rank, and take the top k:
scored = frames if text is not None: # clip_emb · encode(text): one similarity per frame, joined on ( sims = np.asarray(frames.select("clip_emb").to_pydict()["clip_emb"]) @ encode(text) scored = scored.join(sim_table(frames, sims), on=["episode_index if predicate is not None: # the pose scenario, e.g. hammer_grip(hand, thr) scored = scored.where(predicate)
score = (col("sim").max() if text is not None else col("frame_index").count()).alias("score") ranked = ( scored.groupby("episode_index") .agg(col("frame_index").count().alias("n_frames"), score) .sort("score", desc=True) .limit(k) ) The matched frames of the top-k episodes are then stitched into contiguous [start, end] segments (short gaps bridged), which is what makes a hit navigable — you jump to each moment the query is true instead of watching the whole episode.
Check out what these return!
Results
We built a custom UI to try out specific states/actions + user-specific semantic text. Our UI is able to return the top K matching episodes with the specific query-matching segments per episode highlighted and navigable. We match on either one of the left or right hand (or both).
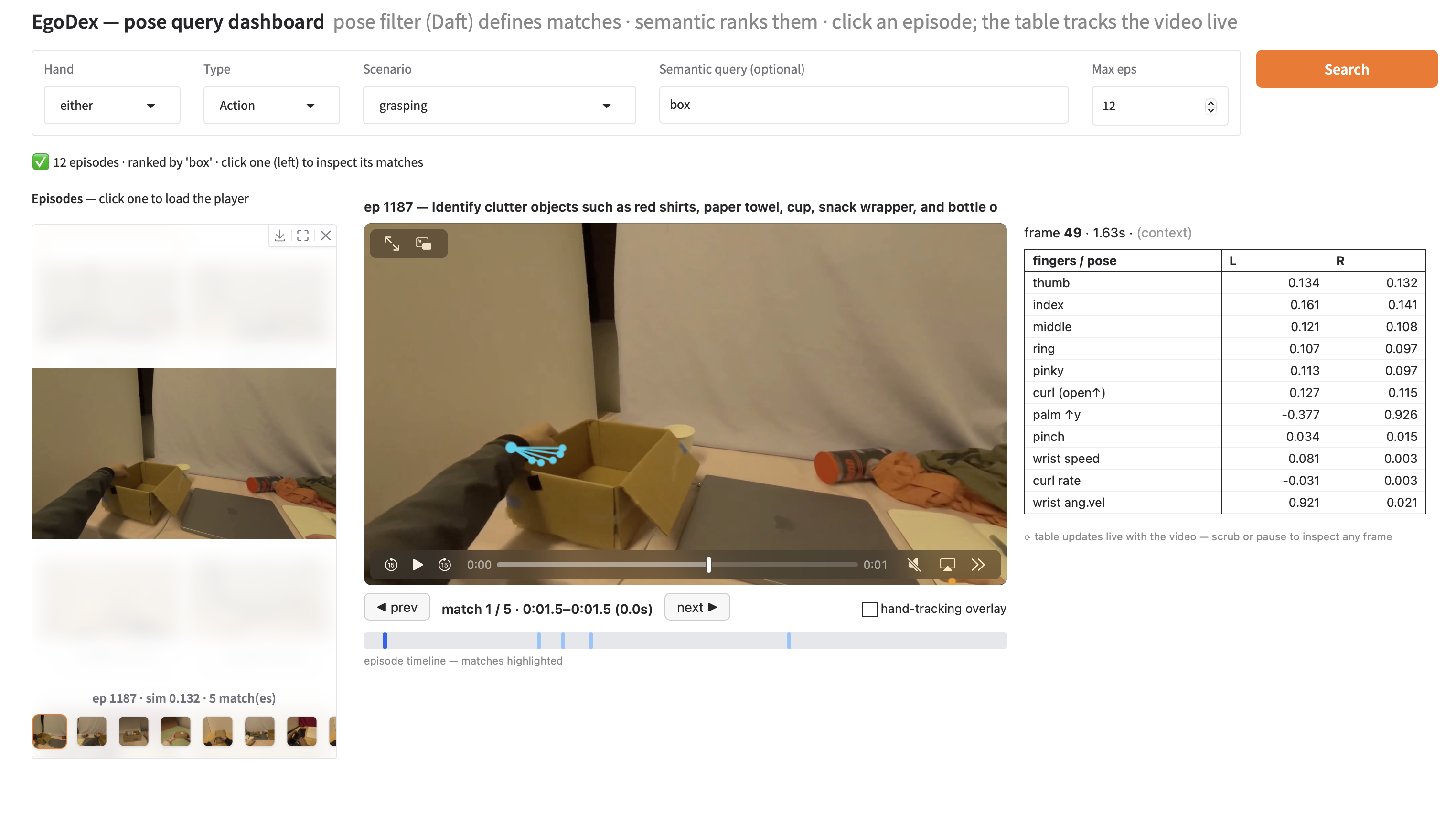
Our query UI: a hand-pose scenario (here "grasping") filters episodes, an optional semantic text query ("box") ranks them, and clicking a result loads a looping clip of the matched segment with a live hand-tracking overlay and per-frame pose table.
We're able to compute [start, end] intervals at which our frames "match" the queried conditions, which allows us to scroll match 1 .. N and see exactly which parts of the episode match our query without having to watch the entire episode.
Here are the results of some of our queries at k=2. Each cell shows the query and the top 2 matched episodes (the matching segment of each is clipped and looped), captioned with the episode's task description.
| Writing grip state only |
① Gather beads using a sweeper brush · ② Fold the paper |
Hammer grip + "stapler" state + semantic |
① Staple paper with a stapler held in hand · ② Put down the black case (failure) |
| Grasping + "shirt" action + semantic |
① Fold a small tshirt · ② Fold a medium-sized tshirt |
Reaching + "marbles" action + semantic |
① Gather the dice into one hand (failure: dice) · ② Collect pebbles on a mancala board |
| In-hand manipulation action only |
① Flick a magnetic ring with the thumb · ② Type on a keyboard |
Lifting action only |
① Lift towels and ducks into a box · ② Assemble soft legos into a tower |
| Open palm state only (most-open band) |
① Braid strands of yarn into a fishtail · ② Distribute pebbles onto the board |
Closed palm state only (most-closed band) |
① Unscrew a screw from a fixture · ② Gather beads using a sweeper brush |
Inside one match: stepping through the segments
A single matched episode usually contains the action several times. Take the lego-tower episode above ("Assemble soft legos into a tower") under the lifting query: the pose predicate is true across 12 separate [start, end] segments — each a distinct lift of a block — which the UI lets you step through one at a time. Here are the first 5:
| Match 1 frames 555–563 |
Match 2 frames 876–882 |
Match 3 frames 1030–1038 |
Match 4 frames 1100–1110 |
Match 5 frames 1259–1273 |
This is what makes the result navigable rather than just a hit: instead of watching the whole episode, you jump straight to each moment the hand lifts a block.
We can see some pretty great successes already.
The pure geometric queries are reliable because they read the sensor data directly: writing grip reveals a hand pinching a sweeper brush and a hand folding paper. Open vs. closed palm cleanly separate a hand splayed to braid yarn from a fist clenched around a screwdriver.
The combined queries are where it gets interesting. Hammer grip + "stapler" puts the actual stapler-in-hand episode at rank 1: neither the pose filter (which finds every power grip) nor the text query (which confuses the black stapler with other dark objects) gets there cleanly alone, but ANDing them does.
Grasping + "shirt" returns two different t-shirt folds, and in-hand manipulation pulls up flicking a magnetic ring and typing on a keyboard, exactly the fine-motor activity the detector was built for.
Where this needs more work
Some failures come from the semantic half, where SigLIP confuses objects that are visually or categorically similar.
"Stapler" → a black case
Querying hammer grip + "stapler" returns the actual stapler episode first, but its second match is an episode that just puts down a small black case. SigLIP is matching on "small dark object held on a table," not on the stapler specifically.
"Marbles" → dice
Reaching + "marbles" returns gathering dice as its top match. Dice and marbles are both small game-table objects, and at SigLIP's resolution they look alike — the model can't tell a cube from a sphere when both are a few pixels of clutter on a desk.
Composition is finicky
A bigger issue hides under the object confusion: "reaching + marbles" is not the query "reaching for marbles." It's two independent filters intersected — frames where the arm is extending, AND frames that look like marbles — with nothing tying the reach to the object. The geometric side knows the hand is reaching but not toward what; the semantic side knows marbles are in view but not that they're the target. The intersection approximates the compositional meaning when the dataset is cooperative and misses it when it isn't. Real relational predicates ("reaching for the marbles," "stapling the paper that was just picked up") need the relationship itself to be modeled, not just the two halves co-occurring.
Some queries we can't express at all
"Episodes where the left hand reaches for the green before the right reaches for the yellow shirt" is a perfectly reasonable thing to ask of a folding dataset — and it's out of reach here. The ordering relationship between the two hands within an episode with relation to semantically-defined objects isn't a column. Some of this is recoverable with more window logic (compare the first reach-onset frame per hand), but most of it needs a better model.
Where this goes next
Closing these gaps is a mix of two things, and they pull in opposite directions.
Better models
A vision-language model could look at a reaching frame and answer "is the hand reaching for the marbles?", resolving the compositionality gap that independent embeddings and geometry can't. The semantic half of the pipeline gets smarter by swapping a stronger model in.
Better domain engineering
More predicates will have to be built by hand against the specific data and shouldn't necessarily be inferred by a model, which is exactly what the geometric features are.
Both problems are supported by first-class primitives in Daft. Domain-specific logic is a UDF (@daft.func / @daft.cls) which is how every geometric feature and the forearm-roll twist detector in this post were built: arbitrary Python and NumPy, dropped in as a column. And Daft is ML-native: SigLIP already runs as a batched GPU UDF inside the pipeline, so upgrading "embed and rank by cosine similarity" to "ask a VLM per frame" is a swap of one UDF, not a new system. With Daft, hand-engineered features and inference live side by side, columns in the same query.
Dataset & license
This post uses EgoDex, Apple’s egocentric hand-manipulation dataset (Hoque et al., 2025). The dataset is released under CC BY-NC-ND 4.0; the ml-egodex code is © 2025 Apple Inc. All video clips shown here are used for non-commercial illustration.
Hoque, R., Huang, P., Yoon, D. J., Sivapurapu, M., & Zhang, J. (2025). EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video. arXiv:2505.11709. https://arxiv.org/abs/2505.11709
@misc{egodex,
title={EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video},
author={Ryan Hoque and Peide Huang and David J. Yoon and Mouli Sivapurapu and Jian Zhang},
year={2025},
eprint={2505.11709},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.11709},
}
